Nuevas estadísticas de rastreo en Google Search Console

«La nueva herramienta de Google Search Console nos da muchas pistas sobre las mejores optimizaciones para nuestra web.»
Hay que celebrar muchísimo esta nueva herramienta en Google Search Console, que nos da muchísima información sobre cómo rastrean los robots de Google nuestra web, y qué detectan. Esta nueva funcionalidad viene a mejorar muchísimo las estadísticas de rastreo que nos ofrecía la anterior herramienta de Google Search Console, y si bien estadísticamente es imperfecto, nos da muchas pistas sobre las posibles optimizaciones que podemos hacer en nuestra web para fomentar que Google pase más a menudo por nuestra web, rastree mejor nuestro contenido, obtenga con más facilidad nuestros recursos.
Esta nueva funcionalidad viene además a democratizar en análisis de logs de Google. El tipo de información que ahora nos proporciona Google sólo estaba hasta hace poco al alcance de solo agencia SEO que monitorizaban los logs de Google en servidor o a través de herramientas complejas como Screaming Frog. Ahora cualquiera puede analizar con un sólo vistazo a Google Search Console cómo Google destripa nuestra web, y obtener información de calidad sobre unos aspectos que afectan, y mucho, a nuestro posicionamiento SEO. Es un anuncio de que a corto o medio plazo, los análisis de logs que se venían haciendo hasta ahora, pueden dejar de ser necesarios.
Esta nueva herramienta SEO ya está disponible para todo el mundo, así de golpe, y ha sido anunciado por Google en su blog para webmasters (muy importante consultar este blog en inglés, pues muchos contenidos Google no los traduce, o cuando lo haga quizá será tarde para nosotros).
Cómo encontrar y sacar partido a las nuevas estadísticas de rastreo de Google
En primer lugar es importante destacar que la nueva herramienta está en ajustes, lo que implica que Google de forma deliberada ha querido escondernos esta nueva herramienta, y no se encuentra a simple vista. Google nos está diciendo: esto no es para todo el mundo, sólo será útil para personas que tengan interés y enfoque en el SEO técnico.
Antes de pasar a analizar los datos desagregados, debes tener en cuenta que los datos que nos ofrece son desde el 1 de noviembre, lo que implica que no hay histórico, y probablemente no lo habrá. El tiempo nos dirá si más adelante nos ofrecerá datos con una cierta perspectiva temporal, pero de saque estos no están.
A continuación analizamos los apartados que encontraremos en el informe uno a uno:
1. Estadísticas generales
Aquí obtenemos una visión general sobre los logs que Google hace en nuestra web. Vemos volumen y evolución en el tiempo de:
- Total de solicitudes
- Tamaño total de la descarga
- Tiempo medio de respuesta
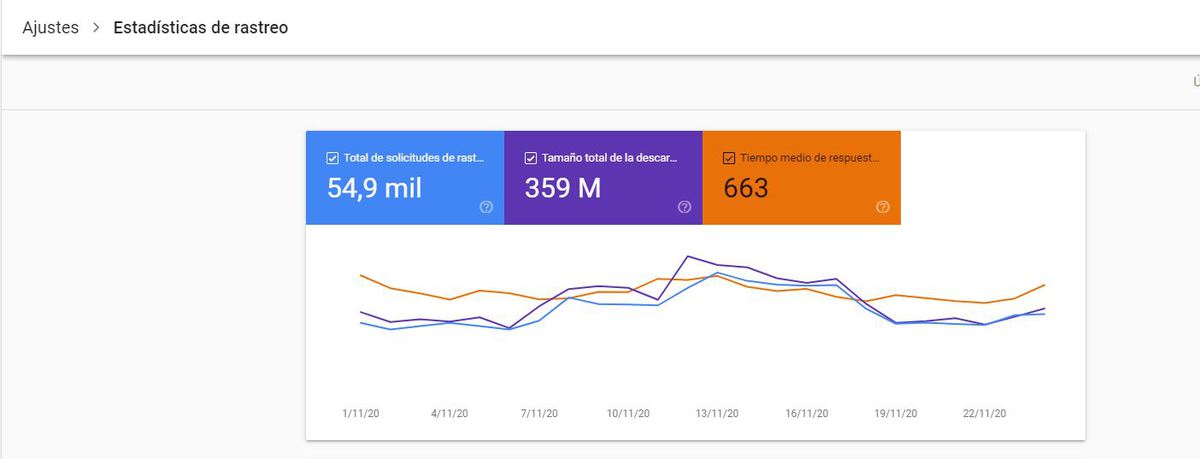
Aquí lo fundamental será observar si vemos que hay cambios destacados en las consultas que Google haga a nuestra web (por lo general, cuantas más, mejor), y el tiempo de respuesta que Google le ha ofrecido a las arañas. Aquí cuanto menor sea ese tiempo de respuesta, mejor experiencia tendrá Google (y los usuarios) en nuestra web, y en consecuencia Google tendrá más tiempo para recorrer el resto de nuestra web y valorar con más detalles nuestros contenidos.
2. Estado del host
Aquí Google nos indica, en líneas generales, cómo está respondiendo nuestro servidor ante sus peticiones. Sirve esencialmente para detectar si nuestro servidor en ocasiones se cae o satura. De forma muy gráfica e intuitiva, veremos unos iconos con tres opciones:
- Verde: el host lleva 90 días sin mostrar problemas graves. Vamos bien
- Rojo: Alarma: tu servidor ha caído o ha dado problemas graves de rastreo a Google. debes tomar medidas
- Verde suave: ya has tomado medidas y la cosa mejora. Llevas ahora entre 1 semana y 89 días limpio y estable, cuando lleves 90 días sin problemas graves, semaforito verde
Este apartado no tiene más, simplemente habrá que irlo observando, si los problemas son recurrentes deberás hacer ajustes en el servidor, o quién sabe, cambiar de hosting.
Ten en cuenta que el semáforo Google lo otorga en base 3 métricas, que además podrás identificar y reparar separadamente:
- Errores de acceso al robots.txt
- Resolución de DNS
- Conectividad de servidor (caídas)
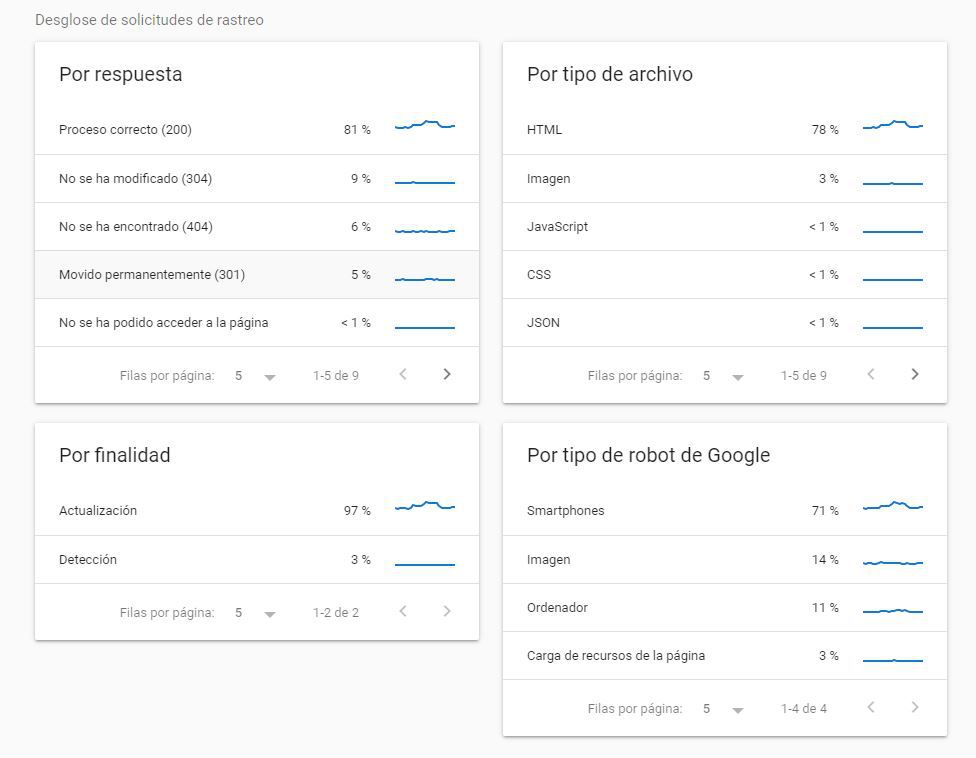
3. Dimensiones: por respuesta
Aquí Google nos indica, en porcentaje, qué conjuntos de código de respuesta le ha dado nuestro servidor a Google. Ojo, los ejemplos que vemos son muestras, no son todas las casuísticas, pero va a ser una guía excelente. Piensa además que si reduces las casuísticas, los ejemplos cada vez se van a acercar más a la realidad. A nivel general, ten en cuenta que las respuestas las podemos agrupar en:
Peticiones probablemente correctas: 200, 300. Ya sabrás que por lo general deberíamos entregar siempre 200 (OK), pero algunos 301 o 302 (redirecciones permanentes o temporales, respectivamente) no son un problema y pueden ayudar, como todo sin abusar.
Peticiones sospechosas: bloqueadas por robots, o 404. Estas respuestas no son malas per se, dependerán de que quieres conseguir. Si una URL ha sido bloqueada por Robots y la quería bloquear, pues estupendo. Si no era mi intención y le estoy ocultando a Google contenido relevante, pues fatal. Igual sucede con los errores 404, no hay que obsesionarse con tener una web sin 404, pues en ocasiones una página deja de existir o tener valor, pues fuera y no pasa nada.
Peticiones malas: estas sí son dañinas en cualquier caso, y debes observarlas y repararlas. Las habituales: robots no disponible, errores 5xx, cualquier error 4xx que no sea 404, error de DNS, DNS no responde, errores de obtención, timeout, errores de redirección, etcétera. Cuantos menor, mejor
Insistimos en un tema que hemos apuntado anteriormente, por si no queda claro: los datos no coinciden 100% con los logs, es un muestreo. Nos permite orientar acciones de mejora, pero no nos va a dar exactitud ni detalles excesivo URL por URL. No sirve para eso, aunque en realidad es posible que no lo necesites.
4. Dimensiones: Por tipo de archivo
Google diferencia los recursos por tipos de archivos (html, imágenes, JS, CSS, JSON, etcétera). Aunque eso ya lo sabíamos, ahora podemos ver en qué porcentaje rastrea cada tipo de recurso. Por lo general y a la espera de cómo evolucionan aspectos como el HTTP2, cuanto más rastreo de HTML mejor, pues es lo que más rápido lee Google, y lo que más va a impactar en nuestro SEO.
Hay un cierto agujero negro en dos apartados que observarás: otro tipo de archivos (aquí hay un poco de todo, y esperemos que con el tiempo separen consultas de sitemaps o robots, por ejemplo), y las solicitudes de errores. Aquí es posible que haya elementos de mejora, pero aun así esta información ya aporta muchísimo valor y es infinitamente mejor que la que teníamos anteriormente.
5. Dimensiones: Por finalidad de rastreo
Este apartado es muy breve y sencillo, y parece tan poca cosa que podemos pasar de puntillas. Y NO. Google distingue entre detección (nueva URL) y actualización. Esto implica que seguramente unos robots se dedican a detectar contenido nuevo en la red, y otros a detectar mejoras y actualizaciones. Y lo más importante: sabemos que para Google hay dos colas de rastreo: la de cosas nuevas, y la de actualizaciones. La primera va más rápido y nos interesa fomentarla. A más novedades, más crawl budget. Es decir, hay que generar contenido nuevo, para que Google pase más a menudo en nuestra web, y la rastree más. Si esto ya lo sabíamos, coge muchísima más importante ahora que Google ya no permite que le enviemos URLs manualmente a indexar. Pista: si he actualizado un contenido con cierta antigüedad, y quiero que Google pase pronto por ahí, ¿qué tal enlazarlo desde la página principal o desde un contenido nuevo?
6. Dimensiones: por tipología de robot
Sabemos que Google tiene un robot para smartphones, uno para Google Ads, uno para carga de recursos de página, y algún otro. Este nuevo informe nos puede orientar respecto a cómo de optimizada está nuestra página para móviles (mobile first indexing), o cuánto tiempo le lleva la carga de recursos en la página. Sobre este tema hay algo que quizá no sepas, o si lo sabes nunca está de más refrescarlo: por una URL Google pasa por primera vez rapidito y obtiene el HTML, y más adelante vuelve para analizar recursos que pesan más y le cuesta renderizar: CSS, JS y demás, para ver la web como el usuario real. Aquí será muy importante agilizar y unificar al máximo la carga de este tipo de recursos, y evitar que algunos de estos bloqueen el renderizado a Googlebot. Por ahora en este campo las webs realizadas con tecnologías como React continúan siendo penalizadas ante el rey PHP, por lo menos de momento, aunque hay señales de que esto puede cambiar en el futuro.
Consejo: valida tu propiedad en Search Console como dominio
En Google Search Console tienes la opción de registrar una sola versión de nuestro dominio (pongamos http://miweb.com), o bien el conjunto del dominio, con todos sus subdominios y protocolos variados. Si tienes la posibilidad siempre es mejor validar, por lo menos, a nivel de dominio. Con la nueva herramienta de estadísticas de rastreo podrás ver una delicia: el estado de los diferentes hosts de la web, que te va a dar pistas sobre las consultas por subdominio, si hemos hecho una migración hacia www o viceversa veremos hasta qué punto Google ya ha hecho su proceso de migración, o bien, como el caso que ilustramos en la captura, nos percatamos de que Google está haciendo peticiones a subdominios que ni siquiera sabíamos que existían, lo que no puede ser bueno.
Conclusiones sobre los nuevos crawl stats de Google Search Console
Con todas las precauciones que se deben tomar ante algo nuevo, y siempre hay que ser cauto, lo que ya hemos visto en los primeros días de su funcionamiento, nos permite afirmar lo siguiente: está muy bien. Es una información muy completa, por fin fácilmente accesible a cualquiera. Avanza el mundo del SEO en dos direcciones que en realidad van de la mano: una mayor democratización de la optimización SEO, que ya no estará sólo al alcance de agencias o profesionales con grandes recursos; y una mayor transparencia de Google respecto a cómo analiza y valora nuestras webs. Cada vez Google tiene menos secretos para nosotros, así lo quieren sus responsables y no podemos hacer más que celebrarlo. El secreto del SEO no es brujería ni nada parecido, es muy sencillo: leer mucho, y trabajar duro. No hay más receta para el éxito en SEO, por lo menos a medio plazo.
PS: si queréis más detalles sobre esta herramienta podéis consultar la documentación de Google.

Bruno Díaz — Marketing Digital
Me gusta el helado de pistacho, escuchar a nuestros clientes y llevarles hasta el infinito... ¡Y más allá!



